概要
RedPen はオープンソースの校正ツールです。RedPen は技術文書が文書規約に従って書かれているかを自動検査します。
RedPen クィックスタート
本節では RedPen をダウンロードしてから利用するところまで解説します。
準備
RedPen を利用するには、以下のソフトウェアが必要です。
-
Java 1.8.40 以上
実行例
はじめに RedPen パッケージを以下のリリースページからダウンロードします。
次に以下のコマンドで RedPen パッケージを解凍してください。
$ tar xvf redpen-*.tar.gz
$ cd redpen-*これで RedPen を利用する準備が整いました。以下のコマンドを実行すると RedPen が動作します。
$ bin/redpen -c conf/redpen-conf-en.xml sample-doc/en/sampledoc-en.txt
<distribution-1.4.1/bin/redpen -c ~/IdeaProjects/redpen/redpen-cli/sample/conf/redpen-conf-en.xml ~/IdeaProjects/redpen/redpen-cli/sample/sample-doc/en/sampledoc-en.txt
[2015-11-16 15:13:03.272][INFO ] cc.redpen.Main - Configuration file: /Users/takahi-i/IdeaProjects/redpen/redpen-cli/sample/conf/redpen-conf-en.xml
[2015-11-16 15:13:03.277][INFO ] cc.redpen.ConfigurationLoader - Loading config from specified config file: "/Users/takahi-i/IdeaProjects/redpen/redpen-cli/sample/conf/redpen-conf-en.xml"
[2015-11-16 15:13:03.285][INFO ] cc.redpen.ConfigurationLoader - Succeeded to load configuration file
[2015-11-16 15:13:03.285][INFO ] cc.redpen.ConfigurationLoader - Language is set to "en"
[2015-11-16 15:13:03.285][WARN ] cc.redpen.ConfigurationLoader - No type configuration...
[2015-11-16 15:13:03.286][INFO ] cc.redpen.ConfigurationLoader - No "symbols" block found in the configuration
[2015-11-16 15:13:03.331][INFO ] cc.redpen.config.SymbolTable - Default symbol settings are loaded
[2015-11-16 15:13:03.334][INFO ] cc.redpen.parser.SentenceExtractor - "[., ?, !]" are added as a end of sentence characters
[2015-11-16 15:13:03.335][INFO ] cc.redpen.parser.SentenceExtractor - "[', "]" are added as a right quotation characters
[2015-11-16 15:13:03.346][INFO ] cc.redpen.validator.Validator - max_len is set to 100
[2015-11-16 15:13:03.349][INFO ] cc.redpen.validator.Validator - max_num is not set. Use default value of 1000
[2015-11-16 15:13:03.350][INFO ] cc.redpen.validator.Validator - max_num is not set. Use default value of 5
[2015-11-16 15:13:03.439][INFO ] cc.redpen.util.DictionaryLoader - Succeeded to load spell dictionary.
[2015-11-16 15:13:03.444][INFO ] cc.redpen.util.DictionaryLoader - Succeeded to load doubled word skip list.
[2015-11-16 15:13:03.449][INFO ] cc.redpen.validator.Validator - leading_word_limit is not set. Use default value of 3
[2015-11-16 15:13:03.449][INFO ] cc.redpen.validator.Validator - percentage_threshold is not set. Use default value of 25
[2015-11-16 15:13:03.449][INFO ] cc.redpen.validator.Validator - min_sentence_count is not set. Use default value of 5
[2015-11-16 15:13:03.451][INFO ] cc.redpen.validator.Validator - min_acronym_length is not set. Use default value of 3
[2015-11-16 15:13:03.453][INFO ] cc.redpen.validator.Validator - deviation_factor is not set. Use default value of 3.0
[2015-11-16 15:13:03.454][INFO ] cc.redpen.validator.Validator - min_word_count is not set. Use default value of 200
[2015-11-16 15:13:03.462][INFO ] cc.redpen.util.DictionaryLoader - Succeeded to load word frequencies.
[2015-11-16 15:13:03.498][INFO ] cc.redpen.validator.Validator - decimal_delimiter_is_comma is not set. Use default value of false
[2015-11-16 15:13:03.499][INFO ] cc.redpen.validator.Validator - ignore_years is not set. Use default value of true
[2015-11-16 15:13:03.499][INFO ] cc.redpen.validator.Validator - max_nesting_level is not set. Use default value of 1
[2015-11-16 15:13:03.499][INFO ] cc.redpen.validator.Validator - max_count is not set. Use default value of 1
[2015-11-16 15:13:03.500][INFO ] cc.redpen.validator.Validator - max_length is not set. Use default value of 3
[2015-11-16 15:13:03.501][INFO ] cc.redpen.util.DictionaryLoader - Succeeded to load weak expressions.
sampledoc-en.txt:1: ValidationError[SymbolWithSpace], Need whitespace before or after symbol "80". at line: Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks , because such software tools make use of large amount of computer resources.
sampledoc-en.txt:3: ValidationError[Spelling], Found possibly misspelled word "distriubuted". at line: Such distriubuted systems need a component to merge the preliminary results from member instnaces.
sampledoc-en.txt:3: ValidationError[Spelling], Found possibly misspelled word "instnaces". at line: Such distriubuted systems need a component to merge the preliminary results from member instnaces.
sampledoc-en.txt:2: ValidationError[Contraction], Found contraction "we'll". at line: In this article, we'll call a computer server that works as a member of a cluster an "instance".
sampledoc-en.txt:1: ValidationError[DoubledWord], Found repeated word "such". at line: Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such softwa re tools make use of large amount of computer resources.
...上記のコマンドにおいて、 -c で指定されている値は設定ファイルパスです。
エラーの意図
前節までで RedPen を起動して入力文書に含まれる悪い点(エラー)を出力する方法について学びました。 しかし RedPen から出力されるエラーをみても、エラーの意図がわからないかもしれません。 そこで RedPen を本格的に利用する前に、エラーの意図について理解する必要があります。
RedPen が提供するエラーの意図について理解するには参考文書、 文書執筆の指南書で解説されている問題点を RedPen で発見する を読むとよいでしょう。
RedPen コマンド
RedPen は2つのコマンドを提供します。RedPen はコマンドラインツールとサーバコマンドを提供します。
コマンドラインツール
RedPen が提供するコマンドラインツールは redpen という名前です。
redpen の使い方
以下は、redpen コマンドが提供するオプションです。
$ redpen [オプション] 入力ファイル(複数可)複数の入力ファイルを指定した際、ファイル間は半角スペースで区切られます。
オプション
redpen コマンドは以下のオプションをサポートしています。
RedPen の設定ファイルを指定
-c <CONFIG_FILE>, --conf <CONFIG_FILE>
設定ファイルを指定しない(-c オプション)場合、redpen は候補を走査します。はじめに redpen はカレントディレクトリにある redpen-conf.xml というファイルがあるかチェックします。存在する場合には設定ファイルとしてロードします。もし無い場合にはカレントディレクトリにある redpen-conf-{lang}.xml をロードします。ここで {lang} は ISO 639-1 で表されれる言語コードです。言語コードはご利用環境の LOCALE 設定に依存します。redpen-conf-{lang}.xml も存在しない場合には、$REDPEN_HOME/conf にある設定ファイルがロードされます。
入力フォーマット [デフォルト: plain]
-f <INPUT_FORMAT>, --format <INPUT_FORMAT>
以下のフォーマットをサポートします。
| 値 | 解説 |
|---|---|
plain |
平文 |
wiki |
Wiki (Textile) フォーマット |
markdown |
Markdown フォーマット |
asciidoc |
AsciiDoc フォーマット |
review |
Re:VIEW フォーマット |
latex |
LaTeX フォーマット |
properties |
Java プロパティファイルフォーマット |
rest |
reStructuredTextフォーマット |
|
Note
|
入力フォーマットの指定がない場合、RedPen はファイル拡張子からフォーマットを推測します。以下は RedPen が理解するファイルフォーマットと拡張子の一覧です。 |
| 値 | 拡張子 |
|---|---|
plain |
txt |
wiki |
wiki |
markdown |
md, markdown |
asciidoc |
adoc, asciidoc |
review |
re, review |
latex |
tex, latex |
properties |
properties |
rest |
rest, rst |
出力フォーマット [デフォルト: plain]
option:: -r <RESULT_FORMAT>, --result_format <RESULT_FORMAT>
redpen は以下の出力フォーマットをサポートします。
| 値 | 解説 |
|---|---|
plain |
平文 |
plain2 |
平文(文ごとのエラーを出力) |
xml |
xml フォーマット |
json |
json フォーマット |
json2 |
json フォーマット(文ごとのエラーを出力) |
許容するエラー数の指定
redpen コマンドは入力文書に含まれるエラー数が指定された値以下の場合 0 を返します。
option:: -l <LIMIT NUMBER>, --limit <LIMIT NUMBER>
エラーメッセージの言語を指定 [デフォルト値: 環境のロケール設定に依存します]
出力されるエラーメッセージの言語(en、ja)を選択できます。
option:: -L <LANGUAGE>,--lang <LANGUAGE>
入力文を指定
redpen コマンドは指定された文をパラメタとして渡せます。主にテスト目的で利用します。
option:: -s <INPUT SENTENCE>, --sentence <INPUT SENTENCE>
ヘルプの出力
-h, --help
バージョンの出力
--version
RedPen サーバ
RedPen はサーバ機能を提供します。RedPen サーバは UI のほかに、REST API も提供します(RedPen サーバ 節参照)。 以下 RedPen サーバ の UI です。
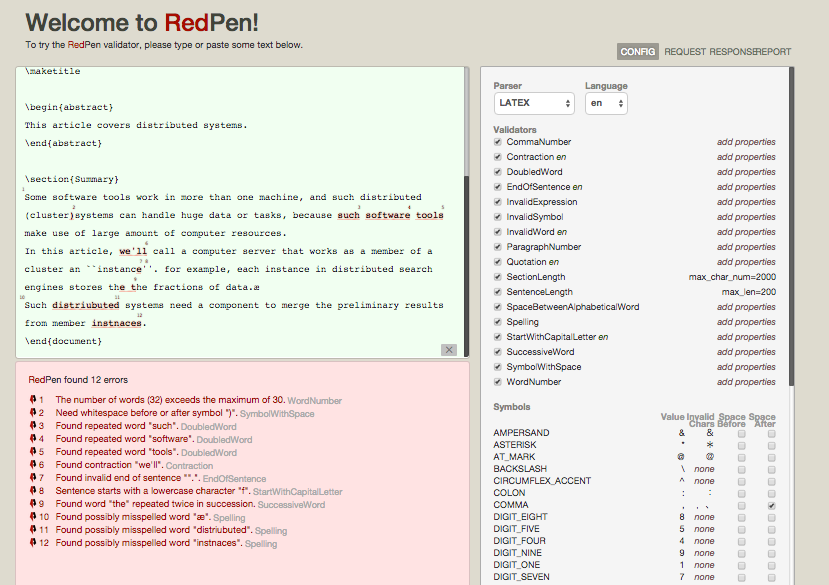
redpen-server の使い方
RedPen サーバは redpen-server コマンドで起動(終了)できます。
$ redpen-server [start|stop]設定
redpen-server の設定は、 redpen-server コマンドファイル自身に記載されています。設定を変更するにはコマンドファイルを編集します。 以下が設定できる項目となります。
| 設定 | デフォルト値 | 解説 |
|---|---|---|
REDPEN_PORT |
8080 |
RedPen サーバが利用するポート番号 |
STOP_KEY |
redpen.stop |
RedPen サーバはストップキーを登録すると http 経由で終了できます。http 経由で終了させたくない場合にはコメントアウトしてください。 |
REDPEN_CONF_FILE |
なし |
RedPen の設定ファイルです。指定する設定ファイルおよびリソース(JavaScript 拡張など)は RedPen のインストールディレクトリ(REDPEN_HOME)以下に保存してください。ファイルが REDPEN_HOME 以下に無い場合には、設定を読み込めません |
REDPEN_LANGUAGE |
環境のロケール設定に依存 |
RedPen から出力されるエラーメッセージの言語を選択します。 |
サーバが提供する機能については RedPen サーバ 節を参照してください。
RedPen 出力フォーマット
RedPen はいくつかの出力フォーマットをサポートしています。
|
Note
|
RedPen v1.10 からエラーのレベルを指定できるようになりました(default は error)。設定法については節、機能(Validator)設定を参照してください。 |
平文(plain)
平文を指定すると RedPen が返すエラーは、以下のフォーマットで出力されます。
FILE_NAME:LINE_NUM: Validation[Error|Info|Warn][ERROR_TYPE], ERROR_MESSAGE at line: SENTENCE
plain2 を指定した場合には、各文ごとのエラーがまとまって出力されます。
XML(xml)
XML 出力フォーマットの最上位ブロックは validation-result です。 validation-result は複数の error ブロックを持ちます。error ブロック は以下の子要素を含んでいます。
ブロック |
必須 |
解説 |
|
false |
機能(Validator)名 |
|
false |
エラーメッセージ |
|
false |
エラーが検知された行 |
|
false |
エラーが検知された文 |
|
true |
ファイル名 |
|
String |
エラーレベル(Info、Warn、Error) |
JSON
RedPen は二種類の JSON での出力をサポートしています(json と json2)。
json
ファイル毎にエラーのリストが出力されます。"document" ブロックにはファイルの名前、"errors" にはファイル内で発見されたエラーが列挙されます。以下は json の出力例です。
[
{
"document": "sample.txt",
"errors": [
{
"sentence": "これはは嬉しい。",
"endPosition": {
"offset": 4,
"lineNum": 1
},
"validator": "DoubledWord",
"lineNum": 1,
"level" : "Error",
"sentenceStartColumnNum": 0,
"message": "Found repeated word \"は\".",
"startPosition": {
"offset": 3,
"lineNum": 1
}
},
{
"sentence": "これはは嬉しい。",
"endPosition": {
"offset": 4,
"lineNum": 1
},
"validator": "SuccessiveWord",
"lineNum": 1,
"level" : "Error",
"sentenceStartColumnNum": 0,
"message": "Found word \"は\" repeated twice in succession.",
"startPosition": {
"offset": 3,
"lineNum": 1
}
}
]
}
]
各エラーは以下の要素を保持します。
ブロック |
必須 |
解説 |
|
false |
機能(Validator)名 |
|
false |
エラーメッセージ |
|
false |
エラーが発生した行番号(非推奨、startPositionを利用してください) |
|
false |
エラーが検知された文 |
|
true |
ファイル名 |
|
true |
エラーの開始位置 |
|
true |
エラーの終了位置 |
|
String |
エラーレベル(Info、Warn、Error) |
|
true |
エラーが発生した列番号(非推奨、startPosition を利用してください) |
json2
json2 も RedPen の結果を JSON フォーマットで返します。json2 では出力が文(センテンス)単位に出力されます。json と同様、json2 は各ファイル毎に "document" と "errors" 要素をもつブロックを生成します。以下 json2 フォーマットの出力例です。
[
{
"document": "sample.txt",
"errors": [
{
"sentence": "これはは嬉しい。",
"position": {
"start": {
"offset": 0,
"line": 1
},
"end": {
"offset": 7,
"line": 1
}
},
"errors": [
{
"subsentence": {
"offset": 3,
"length": 1
},
"validator": "DoubledWord",
"level" : "Error",
"position": {
"start": {
"offset": 3,
"line": 1
},
"end": {
"offset": 4,
"line": 1
}
},
"message": "Found repeated word \"は\"."
},
{
"subsentence": {
"offset": 3,
"length": 1
},
"validator": "SuccessiveWord",
"level" : "Error",
"position": {
"start": {
"offset": 3,
"line": 1
},
"end": {
"offset": 4,
"line": 1
}
},
"message": "Found word \"は\" repeated twice in succession."
}
]
}
]
}
]
json2 の errors は3つの要素からなるブロックです。以下は各要素の解説です。
ブロック |
必須 |
解説 |
|
true |
文(センテンス) |
|
true |
文に含まれるエラーのリスト |
|
true |
文の位置(開始、終了) |
errors は文に含まれるエラーのリストです。各エラーは以下の要素をふくむブロックで表現されます。
ブロック |
必須 |
解説 |
|
true |
機能(Validator)名 |
|
true |
エラーメッセージ |
|
true |
エラーが検知された位置(開始位置と長さ) |
|
true |
エラーの位置(開始、終了) |
|
true |
エラーの終了位置 |
|
String |
エラーレベル(Info、Warn、Error) |
RedPen が提供する機能
RedPen は以下の機能を提供します。
SentenceLength
SentenceLength は入力文書に存在する各文(センテンス)の長さに関する規約が守られているかを検査します。 具体的には文書内の各文が指定された最大文長より長い場合、エラーを出力します。
プロパティ
| プロパティ | デフォルト値 | 解説 |
|---|---|---|
|
100 |
最大文長 |
対応言語
どの言語にも対応しています。
InvalidExpression
入力に不正な表現(単語や句)が存在するか検査します。不正な表現が存在すると InvalidExpression はエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
None |
ユーザ辞書ファイル |
|
None |
不正表現のリスト(コンマ区切り) |
InvalidExpression で指定される辞書は改行区切りです。以下辞書の例となります。
オワタ 馬鹿 ...
対応言語
どの言語にも対応しています。
InvalidWord
InvalidWord は入力文に不正な単語が存在するかを検査します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
None |
ユーザ辞書ファイル |
|
None |
不正単語のリスト(コンマ区切り) |
InvalidWord で指定される辞書は改行区切りです。以下辞書の例となります。
like hey wow ...
対応言語
単語の境界が曖昧な言語(日本語、中国語)では動作しません。
SpaceBeginningOfSentence
|
Warning
|
VoidSection の実装に問題がみつかりました。現在 Deprecated が指定されています。くわしくは こちら |
SpaceBeginningOfSentence は文(センテンス)間に半角スペースが存在するかを検査します。
Properties
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
false |
false では空白が矯正される。true では禁止される。 |
|
"" |
指定されたシンボル(複数指定できる)の前に半角スペースがなくても、エラーは起こらない。 |
|
"" |
指定されたシンボル(複数指定できる)の後に半角スペースがなくても、エラーは起こらない。 |
対応言語
SpaceBeginningOfSentence はどの言語にも対応しています。
CommaNumber
CommaNumber は一文(センテンス)で利用されるコンマの数が指定された最大数よりも多いときにエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
3 |
一文に存在する最大のコンマ数 |
対応言語
どの言語にも対応しています。
WordNumber
WordNumber は一文内の単語数を検査します。文内の単語数が指定した数よりも大きいとき、WordNumber はエラー出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
50 |
一文内で使用できる単語数の上限 |
対応言語
単語の境界が曖昧な言語(日本語、中国語)では動作しません。
SuggestExpression
SuggestExpression は InvalidExpression と同様に動作します。 入力文で不正な表現が使用されているとエラーを出力します。出力されるエラーには利用すべき正しい表現が含まれます。
プロパティ
| プロパティ | デフォルト | 記述 |
|---|---|---|
|
None |
ユーザ辞書 |
|
None |
ペア要素からなるリスト。 例: |
辞書は二カラムのタブ区切り(TSV)フォーマットです。 一列目、二列目にそれぞれ誤った表現、正しい表現を記述します。 以下辞書のサンプルとなります。
like such as asap as soon as possible ...
対応言語
どの言語にも対応しています。
InvalidSymbol
シンボルによっては代替のシンボルが存在します。 たとえばクエスチョンマーク ?(0x003F) は代替のシンボル ?(0xFF1F) が Unicode に登録されています。 InvalidSymbol は入力文で不正なシンボルが利用されているとエラーを出力します。
使用するシンボルに関する設定は設定ファイルの symbols ブロックで指定します。 詳しくは シンボル設定 節を参照してください。
対応言語
InvalidSymbol はどの言語でも動作します。
SymbolWithSpace
シンボルによっては前もしくは後にスペースが必要です。 たとえば、左括弧 "(" の前には、かならず半角スペースを置くという規約がありえます。 スペースに関する設定は設定ファイルの symbols ブロックで指定します。
対応言語
どの言語でも動作します。
KatakanaEndHyphen
カタカナ単語の語尾が規約(JIS Z8301 、G.6.2.2 b 、G.3.)に従っているかを検査します。 具体的には以下のルールが適用されます。
-
a: 単語が三文字もしくはそれ以上の場合には、ハイフンで単語は終わらない。
-
b: 単語が二文字もしくはそれ以下の場合には、単語はハイフンで終わってもよい。
-
c: 単語が複合語の場合には各々の部分単語について条件が適用される。
-
d: a から c のルールにおいて、拗音をのぞきハイフンは一文字としてカウントされます。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
None |
無視したい単語用の辞書(コンマ区切り) |
対応言語
日本語にのみ適用できます。
KatakanaSpellCheck
KatakanaSpellCheck はカタカナ単語のスペリングを検査します。 対象となるカタカナ単語に類似する単語が存在した場合、エラーを出力します。 たとえば、"インデックス"と"インデクス"が同一文書で利用されているときにエラーを出力します。
プロパティ
| プロパティ | デフォルト | 記述 |
|---|---|---|
|
None |
辞書ファイル |
|
0.2 |
類似度の閾値。KatakanaSpellCheck は文書内で使用されたふたつのカタカナ単語のペアの類似度が閾値以下の時にエラーを出力します。なお類似度として編集距離を使用しています。 |
|
5 |
最小頻度。KatakanaSpellCheck は最小閾値以下の単語のみを検査対象とします。 |
対象言語
KatakanaSpellCheck は日本語のみに対応しています。
SectionLength
SectionLength は節で利用できる単語の数を指定します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
1000 |
節内で利用する単語の最大数 |
対応言語
SectionLength はどの言語でも動作します。
ParagraphNumber
ParagraphNumber は節の中に存在してよいパラグラフの最大数を指定します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
5 |
1つの節に存在するパラグラフの最大数 |
対応言語
どの言語でも動作します。
ParagraphStartWith
ParagraphStartWith はパラグラフの開始部分が指定された規約に従っているかを検査します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
" " |
パラグラフ開始部分の文字列 |
Supported languages
どの言語でも動作します。
SpaceBetweenAlphabeticalWord
アルファベット単語の前後に空白が存在するかを検査します。 単語が空白によって区切られない言語(日本語、中国語など)で執筆するときに使用します。 SpaceBetweenAlphabeticalWord はアルファベット単語の前後に空白が存在しないとエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
false |
空白が存在すべき(false)か存在すべきでない(true)か |
対応言語
日本語や中国語など単語がスペースで区切られていない言語に適用できます。
Contraction
Contraction は入力文書で省略表現が利用されたときにエラーを出力します。
対応言語
英語のみです。
Spelling
Spelling は文書内でスペルミスが起こった時にエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
None |
ユーザの辞書 |
|
None |
ユーザ辞書(コンマ区切り) |
対応言語
英語のみです。
DoubledWord
DoubledWord は一文内で二回以上、同一の単語が使用されたときにエラーを出力します。 たとえば、以下の文では良いが二回使われているので、エラーを出力します。
この良い本は良いね。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
None |
スキップリスト用の辞書 |
|
None |
スキップリスト(コンマ区切り) |
対応言語
単語が空白区切りされない多くの言語(中国語、タイ語など)に対応していません。 日本語は動作します。
SuccessiveWord
SuccessiveWord は同一の単語が連続して使用されたときにエラーを出力します。
たとえば入力文書に以下の文が含まれていると、エラーを出力します。 以下の文は、言語という単語を連続(書き誤り)で使用しています。
日本語はいい言語言語だ。
対応言語
日本語を除く、単語が空白区切りされない言語には対応していません。
DuplicatedSection
文書中に著しく類似する節が存在すると、エラーを出力します。 類似度はコサイン距離によって計算されます。
対応言語
どの言語でも動作します。
JapaneseStyle
ですます調とである調が混在して利用された場合、エラーを出力します。
対応言語
日本語のみに対応しています。
DoubleNegative
DoubleNegative は入力文書に二重否定が使用されているとエラーを出力します。
対応言語
日本語のみに対応しています。
FrequentSentenceStart
多くの文が同一表現から開始されているときにエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
3 |
考慮する先頭からの単語数 |
|
25 |
同一の文頭表現が利用された最大パーセント |
|
5 |
エラーが起こる最小の文数。文書内の文が指定値よりも少ないとエラーは出力されません。 |
対応言語
中国語、タイ語などトークナイザが対応していない言語以外は動作します。
UnexpandedAcronym
UnexpandedAcronym は省略形で書かれている単語の正式表記が文中に存在するかを検査します。
たとえばもし ABC という省略形で書かれた単語が存在した場合を考えます。 このとき、UnexpandedAcronym は文書中に ABC の正式表記が含まれているかを検査します。 正式表記は Axxx Bxx Cxxx という単語列です。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
3 |
省略形の最小文字数 |
対応言語
UnexpandedAcronym は英語のみ動作します。
WordFrequency
WordFrequency は文中で使用されている単語が一般的な単語の頻度とくらべ異なる際にエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
3 |
単語使用頻度の偏差許容因子。例えば通常3%の出現頻度の単語であれば文書全体で9%まで使用できます。 |
|
200 |
検査前における文書内の最低単語数 |
Supported languages
英語のみに対応しています。
Hyphenation
Hyphenation ハイフンで連結された単語列が一般的な利用方法にマッチしているかを検査します。
Supported languages
英語のみに対応しています。
NumberFormat
NumberFormat は文中の数値表現が一般的な記法に従っているかを検査します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
false |
数値のデリミタを . から , に変更する(ヨーロッパ方式) |
|
true |
四桁の数値を無視する(2015, 1998など) |
対応言語
ヨーロッパ系の言語に対応しています。
ParenthesizedSentence
ParenthesizedSentence は括弧に関する規約を検査します。 検査するポイントは以下の3つです。
-
一文内で使用される括弧の使用頻度
-
ネストされた括弧が存在するか
-
括弧の開始位置から終了位置までの長さ
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
2 |
一文に存在してよい括弧のネスト数 |
|
1 |
一文内に存在してよい括弧の上限数 |
|
4 |
括弧内に存在してもよい単語数の上限 |
対象言語
どの言語でも動作します。
JavaScript
JavaScript は機能拡張スクリプトを実行します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
|
機能拡張スクリプトを走査するパス。 |
対象言語
どの言語でも動作します。
DoubledJoshi
DoubledJoshi は同一の助詞が一文で二回以上、利用されているとエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
None |
ユーザ辞書ファイル |
|
None |
助詞のスキップリスト(コンマ区切り) |
|
1 |
助詞の最低間隔値 。textlint-rule-no-doubled-joshiにならって導入しました。詳しくは こちら を確認してください。 |
対象言語
日本語のみサポートしています。
HankakuKana
文書中に半角カナ文字が利用されているとエラーを出力します。
対象言語
日本語のみ動作します。
Okurigana
送りがなの使い方が正しくない場合にエラーを出力します。
対象言語
日本語のみ動作します。
StartWithCapitalLetter
文が小文字から始まっている場合にエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
None |
ユーザの辞書(スキップリスト) |
|
None |
ユーザ辞書(コンマ区切り) |
対象言語
英語およびラテン系の言語で動作します。
VoidSection
節に段落や文が1つも含まれていない場合にエラーを出力します。
|
Warning
|
VoidSection は Deprecated です。将来的に削除されます。かわりに EmptySection をご利用ください。 |
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
5 |
指定したレベル以下の節に対して検査をスキップする。 |
対象言語
どの言語でも動作します。
EmptySection
節に段落や文が1つも含まれていない場合にエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
5 |
指定したレベル以下の節に対して検査をスキップする。 |
対象言語
どの言語でも動作します。
GappedSection
GappedSection は節(章)の大きさにギャップがあるとエラーを出力します。 たとえば、以下のテキストでは 1 節の直下に 1.1.1 節があります。 つまり 1 節と 1.1.1 節の間にギャップが存在します。 ギャップを埋めるためには、1.1.1 節の前に 1.1 節が存在するべきです。
# 1 節 ... ### 1.1.1 節 ### 1.1.2 節 ...
対象言語
どの言語でも動作します。
LongKanjiChain
長すぎる熟語(漢字の連続)を検出し、エラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
2 |
熟語の最大長 |
対象言語
日本語のみサポートしています。
SectionLevel
深すぎる節を検出しエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
5 |
節の最大深度 |
対象言語
どの言語でも動作します。
JapaneseAmbiguousNounConjunction
日本語文に含まれる、曖昧な名詞接続のパターンを検出しエラーを出力します。 ここで、曖昧な名詞接続のパターンとは、格助詞の "の" + 名詞連続 + 各助詞の "の" です。 たとえば以下の文は、曖昧な名詞接続を含んでいます。
弊社の経営方針の説明を受けた。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
None |
ユーザ辞書ファイル(スキップリスト) |
|
None |
スキップリスト(コンマ区切り) |
Supported languages
日本語のみサポートしています。
JapaneseJoyoKanji
常用漢字以外の漢字を検出しエラーを出力します。
たとえば以下の文は、常用漢字でない漢字(踵)を含んでいます。
踵を返して出て行った。
Supported languages
日本語のみサポートしています。
JapaneseExpressionVariation
JapaneseExpressionVariation は表記ゆれの可能性を検知します。 この機能は KatakanaSpellCheck と同様です。両者違いは JapaneseExpressionVariation がカタカナ単語だけでなるあらゆる種類の単語を対象に表記ゆれを検知する点です。
|
Warning
|
この機能からの出力には問題ない点も含まれます。エラーレベルを info に設定して、出力は参考情報としてお使いください。
|
Properties
| Property | Default Value | Description |
|---|---|---|
|
None |
ユーザ辞書 |
|
None |
ペア要素からなるリスト。 e.g. |
Supported languages
JapaneseNumberExpression は日本語のみに対応しています。
JapaneseNumberExpression
日本語文において、計数表現のスタイルが一貫していない箇所を検出しエラーを出力します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
numeric |
使用すべき計数表現のスタイル。四つの値 ("numeric" ・ "numeric-zenkaku" ・ "kansuji" ・ "hiragana")から選択 |
以下は、各値と期待される計数表現の対応をまとめた表です。
| 値 | 計数表現 |
|---|---|
|
1つ、2つ |
|
1つ、2つ |
|
一つ、二つ |
|
ひとつ、ふたつ |
対象言語
日本語のみサポートしています。
JapaneseAnchorExpression
日本語文において、章節の参照が一貫したスタイルになっているか検査します。
プロパティ
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
numeric |
使用すべきスタイル。三つの値 ("numeric" ・ "numeric-zenkaku" ・ "kansuji" )から選択 |
以下は、値と期待される表現の対応をまとめた表です。
| 値 | 計数表現 |
|---|---|
|
1章、1.2節 |
|
1章、2節 |
|
一章、二節 |
対象言語
日本語のみサポートしています。
SuccessiveSentence
SuccessiveSentence は同一の文が二回連続で使用されるとエラーを出力します。
たとえば入力文書に以下のパラグラフが含まれていると、エラーを出力します。
いつも感じるのです。日本語はよい言語だ。日本語はよい言語だ。それでも別の言語もよい点が色々あります。
上記のパラグラフには同一の文 "日本語はよい言語だ。" が二回連続で出現しています。
Properties
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
3 |
文書中で連続する二文から計算される 編集距離 のしきい値。算出された距離がしきい値よりも小さな場合にエラーを出力する |
|
5 |
本機能が対象とする文長の最小値 |
対応言語
どの言語にも対応しています。
DoubledConjunctiveParticleGa
一文に二回以上、接続助詞の が が出現するとエラーを出力します。たとえば、DoubledConjunctiveParticleGa は以下の文に対してエラーを出力します。
今日は早朝から出発したが、定刻通りではなかったが、無事会場に到着した。
対象言語
日本語のみサポートしています。
ListLevel
ListLevel は入力文書内に含まれるリスト項目の階層を検査します。 リスト項目の階層が指定された最大値よりも深い場合、エラーを出力します。
Properties
| プロパティ | デフォルト | 解説 |
|---|---|---|
|
5 |
リスト項目の最大深度 |
例えば max_level を 5 に設定して以下の入力を与えた場合、六番目のリスト項目に対しエラーが出力されます。
* one ** two *** three **** four ***** five ****** six
対応言語
どの言語にも対応しています。
RedPen の設定
RedPen は実行方法(コマンラインツール、サーバ)関係なく、設定ファイルを指定して使用します。 RedPen が提供する設定ファイルは2つのブロックからなります。1つ目のブロックは利用する 機能を列挙します。もう1つのブロックは文書内で利用するシンボルを設定します。以下詳しくみていきます。
設定ファイル
RedPen 単一の設定ファイルを持ちます。ファイルは入力ファイルのフォーマットに依存しない設定項目すべてが含まれます。 設定ファイルは XML フォーマットで記述されます。XML のルート(root)ブロックは "redpen-conf" です。 "root-conf" ブロックは2つの子ブロック("validators" と "symbols")を持ちます。
validators には RedPen で利用する機能(validator)を列挙します。validator には property を指定できるものがあります。 property を利用すると、機能の挙動がデフォルトから変更できます。
symbols ブロックは言語ごとに存在するデフォルトのシンボル設定を上書きます。 デフォルトのシンボル設定には、redpen-conf ブロックがサポートするプロパティ、lang と variant を利用します。
以下は設定ファイルの例です。
<redpen-conf lang="en">
<validators>
<validator name="SentenceLength">
<property name="max_len" value="200"/>
</validator>
<validator name="InvalidSymbol" />
<validator name="SpaceWithSymbol" />
<validator name="SectionLength">
<property name="max_num" value="2000"/>
</validator>
<validator name="ParagraphNumber" />
</validators>
<symbols>
<symbol name="EXCLAMATION_MARK" value="!" invalid-chars="!" after-space="true" />
<symbol name="LEFT_QUOTATION_MARK" value="\'" invalid-chars="“" before-space="true" />
</symbols>
</redpen-conf>次節では機能の設定について詳しく解説をおこないます。 シンボルの設定については シンボル(文字)設定節で解説をおこないます。
機能(Validator)設定
RedPen の設定ファイルは validator ブロックを持ちます。 validator ブロックには、RedPen で検査したい機能を列挙します。
以下は validators ブロックのサンプルです。
<validators>
<validator name="SentenceLength">
<property name="max_len" value="200"/>
</validator>
<validator name="InvalidSymbol" level="info"/>
<validator name="SpaceWithSymbol" />
<validator name="SectionLength" level="warn">
<property name="max_num" value="2000"/>
</validator>
<validator name="ParagraphNumber" />
</validators>各機能は validator 要素で表現されます。 validator 要素の "name" で機能を指定します。 各機能は入力文書がもつ特定の面を検査します。たとえば SentenceLength は 文書内にふくまれる文の長さが指定した上限よりも短いかを検査します。
提供される機能の中には property 要素で設定できるものがあります。 たとえば、SentenceLength で検査する文長の最大値は max_num で指定できます。 各機能の解説については Validator を参照してください。
RedPen v1.10 より、各機能から出力されるエラーのレベルを指定できるようになりました。 指定できるエラーレベルは三種類(info、warn、error)でデフォルト値はエラーです。 たとえば、上の設定ファイルでは InvalidSymbo のエラーレベルは info に設定されています。 入力文書にエラーがあると、エラーレベルはほかのエラー情報とともに出力されます。 くわしくは RedPen 出力フォーマット 節を参照してください。
シンボル(文字)設定
redpen-conf が提供する lang 属性で、入力文書の記述言語を指示します。 lang 属性で記述言語を指定すると、シンボルの基本(デフォルト)設定がロードされます。 RedPen は二言語(英語 "en" と日本語 "ja")の基本設定をサポートしています。 各言語のシンボル設定については 英語シンボル設定 と日本語シンボル設定を参照してください。
デフォルトシンボル設定は、symbols ブロックを設定ファイルに追加すると上書きできます。 symbols ブロックには symbol ブロックを追加します。 symbol ブロックにはシンボル属性をいくつか記述します。シンボル属性は文書を検査する際に利用されます。
以下の表は、symbol で指定する属性について解説しています。
| プロパティ(属性) | 必須 | デフォルト | 解説 |
|---|---|---|---|
|
true |
none |
シンボル名 |
|
true |
none |
シンボルの値(文字) |
|
false |
false |
シンボルの前に半角スペースが必要か |
|
false |
false |
シンボルの後ろに半角スペースが必要か |
|
false |
"" |
使いたくない同意文字のリスト |
サンプル:シンボル設定
以下はシンボルの設定例です。設定例では三種類のシンボルを定義しています。 1つはエクスクラメーションマークです。 2つ目は FULL_STOP です。FULL_STOP には文末文字(ピリオド、句点)を指定します。 文末文字として半角ピリオドを使用する設定がなされてます。さらにピリオドの後ろには半角スペースを必要と指定しています。 最後の要素は、コンマに関する設定です。コンマに関する設定では2つのシンボルを利用できない文字として登録しています。 invalid-chars に登録された文字は InvalidSymbol 機能で利用されます。 invalid-chars に登録された文字が文中であらわれると、InvalidSymbol はエラーを出力します。
<symbols>
<symbol name="EXCLAMATION_MARK" value="!" />
<symbol name="FULL_STOP" value="." after-space="true" />
<symbol name="COMMA" value="," invalid-chars="、," after-space="true" />
</symbols>英語:デフォルト(基本)のシンボル設定
以下は英語の基本シンボル(文字)設定を示しています。
| シンボル | 値 | 前スペース | 後ろスペース | 不正文字リスト | 解説 |
|---|---|---|---|---|---|
|
'.' |
false |
true |
'.', '。' |
Sentence period |
|
' ' |
false |
false |
' ' |
White space between words |
|
'!' |
false |
true |
'!' |
Exclamation mark |
|
'#' |
false |
false |
'#' |
Number sign |
|
'$' |
false |
false |
'$' |
Dollar sign |
|
'%' |
false |
false |
'%' |
Percent sign |
|
'?' |
false |
true |
'?' |
Question mark |
|
'&' |
false |
true |
'&' |
Ampersand |
|
'(' |
true |
false |
'(' |
Left parenthesis |
|
')' |
false |
true |
')' |
Right parenthesis |
|
'*' |
false |
false |
'*' |
Asterrisk |
|
',' |
false |
true |
'、',',' |
Comma |
|
'+' |
false |
false |
'+' |
Plus sign |
|
'-' |
false |
false |
'ー' |
Hyphenation |
|
'/' |
false |
false |
'/' |
Slash |
|
':' |
false |
true |
':' |
Colon |
|
';' |
false |
true |
';' |
Semicolon |
|
'<' |
false |
false |
'<' |
Less than sign |
|
'>' |
false |
false |
'>' |
Greater than sign |
|
'=' |
false |
false |
'=' |
Equal sign |
|
'@' |
false |
false |
'@' |
At mark |
|
'[' |
true |
false |
Left square bracket |
|
|
']' |
false |
true |
Right square bracket |
|
|
'\' |
false |
false |
Backslash |
|
|
'^' |
false |
false |
'^' |
Circumflex accent |
|
'_' |
false |
false |
'_' |
Low line (under bar) |
|
'{' |
true |
false |
'{' |
Left curly bracket |
|
'}' |
true |
false |
'}' |
Right curly bracket |
|
' |
' |
false |
false |
'|' |
Vertical bar |
|
'~' |
false |
false |
'〜' |
Tilde |
|
''' |
false |
false |
|
Left single quotation mark |
|
''' |
false |
false |
|
Right single quotation mark |
|
'"' |
false |
false |
|
Left double quotation mark |
|
'"' |
false |
false |
以下、各列の意味をしめしています。
-
一列目 シンボル名
-
二列目 シンボルの値(文字)
-
三列目 文字の前に半角スペースが必要かを表しています。
-
四列目 文字の後ろにスペースが必要かを示しています。
-
五列目 各シンボルの同意シンボルで使用してはいけないものを列挙しています。
上記シンボルは文(センテンス)の切り出しと、一部機能で利用されます。 たとえば、InvalidSymbol は不正文字リストに登録されたシンボルが入力文で発見されるとエラーを出力します。 SymbolWithSpace は前スペースもしくは後ろスペースの設定と異なる用法が存在した場合にエラーを出力します。 デフォルト設定から変更したい場合は設定ファイルに symbols ブロックを追加します。 追加した symbols ブロック内に変更したい文字の設定を記述します。 くわしくはシンボル(文字)設定節を参照してください。
デフォルトのシンボル設定(日本語)
下表では日本語用のデフォルトシンボル設定が示されています。 表内に存在する各列は英語用シンボル設定の表と同一です。
| シンボル | 値 | 前スペース | 後ろスペース | 不正文字リスト | 解説 |
|---|---|---|---|---|---|
|
'。' |
false |
false |
'.','.' |
Sentence period |
|
' ' |
false |
false |
White space between words |
|
|
'!' |
false |
false |
'!' |
Exclamation mark |
|
'#' |
false |
false |
'#' |
Number sign |
|
'$' |
false |
false |
'$' |
Dollar sign |
|
'%' |
false |
false |
'%' |
Percent sign |
|
'?' |
false |
false |
'?' |
Question mark |
|
'&' |
false |
false |
'&' |
Ampersand |
|
'(' |
false |
false |
'(' |
Left parenthesis |
|
')' |
false |
false |
')' |
Right parenthesis |
|
'*' |
false |
false |
'*' |
Asterrisk |
|
'、' |
false |
false |
',',',' |
Comma |
|
'+' |
false |
false |
'+' |
Plus sign |
|
'ー' |
false |
false |
'-' |
Hyphenation |
|
'/' |
false |
false |
'/' |
Slash |
|
':' |
false |
false |
Colon |
|
|
';' |
false |
false |
Semicolon |
|
|
'<' |
false |
false |
Less than sign |
|
|
'>' |
false |
false |
Greater than sign |
|
|
'=' |
false |
false |
'=' |
Equal sign |
|
'@' |
false |
false |
'@' |
At mark |
|
'「' |
true |
false |
Left square bracket |
|
|
'」' |
false |
false |
Right square bracket |
|
|
'¥' |
false |
false |
Backslash |
|
|
'^' |
false |
false |
'^' |
Circumflex accent |
|
'_' |
false |
false |
'_' |
Low line (under bar) |
|
'{' |
true |
false |
'{' |
Left curly bracket |
|
'}' |
true |
false |
'}' |
Right curly bracket |
|
'|' |
false |
false |
'|' |
Vertical bar |
|
'〜' |
false |
false |
'~' |
Tilde |
|
'‘' |
false |
false |
Left single quotation mark |
|
|
'’' |
false |
false |
Right single quotation mark |
|
|
'“' |
false |
false |
Left double quotation mark |
|
|
'”' |
false |
false |
Right double quotation mark |
日本語における文字設定のバリエーション
日本語の文書で使用される文字は著者や執筆グループによって大きくことなります。 そこで RedPen は日本語用に二種類のバリエーション("zenkaku2" と "hankaku")を提供しています。 文字設定のバリエーションは type もしくは variant 属性で指定します。下記の設定例ではバリエーション、"zenkaku2"を指定しています。
|
Note
|
type と variant 属性には同一の効果があります。現在の RedPen(v1.x)は type を利用できますが、将来的には variant に統一されます。そのため、今のうちから variant 属性の利用をおすすめします。 |
<redpen-conf lang="ja" type="zenkaku2">
<validators>
<validator name="InvalidSymbol" />
<validator name="SpaceWithSymbol" />
<validator name="SectionLength" />
<validator name="ParagraphNumber" />
</validators>
</redpen-conf>hankaku は英語の設定と同一です。zenkaku2 は、ほぼ日本語のデフォルト文字設定と同一です。 以下のシンボルについてのみデフォルトと設定が異なります。
| シンボル | 値 | 前スペース | 後ろスペース | 不正文字リスト | 解説 |
|---|---|---|---|---|---|
FULL_STOP |
'.' |
false |
false |
' .', '。' |
Sentence period |
COMMA |
',' |
false |
false |
',','、' |
Comma |
入力フォーマット
RedPen は数種類のテキストフォーマットに対応しています。以下は対応するテキストフォーマットの一覧です。
-
平文(プレーンテキスト)
-
Markdown
-
AsciiDoc
-
Wiki
-
Re:VIEW
-
LaTeX
-
Java プロパティ
プレーンテキスト
プレーンテキストはパラグラフをサポートしています。 パラグラフは連続する2つの改行によって区切られます。たとえば以下は2つのパラグラフを含んでいます。
This is a first paragraph. This paragraph is the introduction of this article. It introduces the central issue discussed throughout the rest of the article. Second paragraph describes the details of the issue and attempts to present a solution.
AsciiDoc
LaTeX
|
Note
|
自作マクロには対応していません |
Wiki
RedPen は Wiki 記法の一部に対応しています。以下対応した記法の解説となります。
|
Note
|
エラー箇所のポジション情報を出力できません。 |
見出し
見出しを "h[1234]. " で表現します。h につづく数で見出しのレベルを表現します。
インライン表記
いくつかのインライン表記に対応しています。
太字
**this is a Bold sentence.**
イタリック
//this is an italic sentence.//
アンダーライン
__this is an underlined sentence.__
削除線
--this is a strikethrough sentence.--
リスト
パーサは2つのリスト記法に対応しています。
Bulleted リスト
* List * List ** Sub List
Numbered リスト
# List # List ## Sub List
コメント
[!-- This is a comment. --]
パラグラフ
Markdown
Re:VIEW format
Java プロパティ
Java プロパティファイルやリソースバンドルは Java プロジェクトを国際化するために使われます。 RedPen は各プロパティを、複数の文からなる節として取り扱います。コメントと設定値が検査の対象です。キーは検査されません。
Java プロパティファイルのフォーマットについて、詳しくは Java プロパティに関する Javadoc をご参照ください。
アノテーションによるエラーの抑制
RedPen から出力されるエラー(規約違反)を修正したくない場合があります。 RedPen から報告されるエラーを修正したくない状況には、エラーの修正にかかるコストが大きすぎる場合や、明確な理由をもって規約に違反する場合があります。 エラーを修正したくない場合に対応するために、RedPen はアノテーションによってエラーを抑制する機能(エラーの抑制機能)があります。 エラーを抑制するには、抑制用のアノテーションをエラーを含む節の直前に追加します。
現在、エラーの抑制機能は4つ(AsciiDoc、Markdown、Re:VIEW、LaTeX)のフォーマットで利用できます。
AsciiDoc
AsciiDoc でエラーの抑制機能を使うには、アノテーションを AsciiDoc のアトリビュートブロックに追加します。アノテーションは [suppress] です。以下、節に含まれる全てのエラーを抑制する例です。
[suppress]
= Instances
Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk, and Memory.一部のエラーのみを抑制する場合、アノテーション(suppress)につづけて機能(バリデータ)名を追加します。以下の例は、節に含まれる2種類のエラー(Contraction ・ WeakExpression)のみを抑制しています。
[suppress='Contraction WeakExpression']
= Instances
Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk and Memory.|
Note
|
エラーの抑制機能は二重行(two line)スタイルの見出に対応していません。 |
Markdown
Markdown フォーマットの文書でエラー抑制機能を使うには、 HTML コメント内に抑制用のアノテーションを追加します。アノテーションは @suppress です。 以下に示す例では、節内に含まれる全てのエラーを抑制しています。
<!-- @suppress -->
# Instances
Some software tools work in more than one machine, and such _distributed_ (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk and Memory.一部のエラーのみを抑制するには、機能名を抑制アノテーション(@suppress)に続けて追加します。次の例では2種類のエラー(Contraction ・ WeakExpression)のみを抑制しています。
<!-- @suppress Contraction WeakExpression -->
# Instances
Some software tools work in more than one machine, and such _distributed_ (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk and Memory.|
Note
|
複数行にわたる HTML コメントでは抑制用のアノテーションは使用できません。 |
Re:VIEW
Re:VIEW フォーマットの文書でエラー抑制機能を使うには、Re:VIEW コメント( #@# )内に抑制用のアノテーションを追加します。抑制用のアノテーションは @suppress です。以下の例は、節内に含まれる全てのエラーを抑制しています。
#@# @suppress
= Instances
Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk and Memory.一部のエラーだけを抑制するには、機能の名前を抑制用のアノテーション(@suppress)に続けて追加します。次の例では2種類のエラー(Contraction ・ WeakExpression)のみを抑制しています。
#@# @suppress Contraction WeakExpression
= Instances
Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources, such as CPU, Disk and Memory.LaTeX
LaTeX フォーマットの文書でエラー抑制の機能を使うには、LaTeX コメント( % )内に抑制アノテーションを追加します。記述する抑制用のアノテーションは Markdown フォーマットと同じです。
reStructuredText
reStructured フォーマットの文書でエラー抑制の機能を使うには、inline コメント( .. )内に抑制アノテーションを追加します。以下は抑制アノテーションのサンプルです。
.. @suppress Contraction WeakExpression
Distributed system
##################
Some software tools work in more than one machine, and such distributed (cluster)systems can handle huge data or tasks, because such software tools make use of large amount of computer resources.RedPen を拡張する
ユーザは自身で RedPen を拡張(機能追加)できます。 本節では機能追加の方法と RedPen が内部に保持する文書モデルについて解説します。 RedPen では Java と JavaScript を利用して機能を拡張できます。
Java による拡張の作成
Java で機能拡張を作成するには抽象クラス(Validator)を実装します。
Validator クラスの拡張
Validator クラスには実装できるメソッドがいくつか(validate ・ prevalidate ・ init)提供されています。 以下各メソッドについて解説します。
validate メソッド
機能を作成するには、validate メソッドの実装が必要です。 validate メソッドには引数によっていくつかのバリエーションがあります。 現状では三種類の validate メソッドが提供されています。
/**
* validate the input document and returns the invalid points.
* {@link cc.redpen.validator.Validator} provides empty implementation. Validator implementation validates documents can override this method.
*
* @param document input
*/
public void validate(Document document)
/**
* validate the input document and returns the invalid points.
* {@link cc.redpen.validator.Validator} provides empty implementation. Validator implementation validates sentences can override this method.
*
* @param sentence input
*/
public void validate(Sentence sentence)
/**
* validate the input document and returns the invalid points.
* {@link cc.redpen.validator.Validator} provides empty implementation. Validator implementation validates sections can override this method.
*
* @param section input
*/
public void validate(Section section)|
Note
|
実装されたクラスは特定のパッケージに属す必要があります。利用できるパッケージは cc.redpen.validator ・ cc.redpen.validator.sentence ・ cc.redpen.validator.section です。 |
prevalidate メソッド
preValidate は validate が呼び出される前に実行されます。preValidate メソッドを validate メソッドの前処理として利用すると便利です。 現在、二種類の prevalidate メソッドが提供されています。
/**
* Process input blocks before run validation. This method is used to store
* the information needed to run Validator before the validation process.
*
* @param sentence input sentence
*/
public void preValidate(Sentence sentence)
/**
* Process input blocks before run validation. This method is used to store
* the information needed to run Validator before the validation process.
*
* @param section input section
*/
public void preValidate(Section section)設定項目
validator の動作にあたって設定項目(プロパティ)を必要とする場合があります。その場合、validator のコンストラクタで必要なプロパティを定義します。 コンストラクタで定義すると、RedPen は各 validator についてプロパティが必要かを判断できます。
/**
* @param keyValues String key and Object value pairs for supported config properties.
*/
public Validator(Object...keyValues)たとえば SentencelengthValidator は max_len というプロパティを提供します。 max_len は入力文書で許される一文の最大長を指定します。以下は文の最大長を二百に指定した設定例となります。
<redpen-conf>
<validators>
...
<validator name="SentenceLength">
<property name="max_len" value="200"/>
</validator>
...
</validators>
</redpen-conf>SentenceLengthValidator の作成時に max_len 値が設定ファイルから読み込まれます。 設定ファイルにおいて max_len が定義されていない場合は、デフォルト値が使用されます。
public SentenceLengthValidator() {
super("max_len", 30); // Default maximum length of sentences.
}一旦設定されたプロパティは、getInt("プロパティ名") のように参照できます。
validate メソッドの実行前にプロパティを前処理しておきたいことがあります。その場合は init メソッドをオーバーライドしてください。
作成した Validator の追加
RedPen に作成した Validator を追加する方法は二通りあります。
1つは、機能拡張(Validator)用ファイルを、RedPen のソースに追加してビルドする方法です。 この方法は簡単です。しかし機能拡張のソースファイルを RedPen ソースファイル群と同梱して扱う必要があります。
もう1つの方法はプラグインを作る方法です。プラグインの場合には、機能拡張ソースファイルを RedPen から独立して扱えます。
|
Note
|
どちらの方法でもファイル名に制約があります。ファイル名は語尾(サフィックス)、Validator で終わる必要があります。クラス名が Validator で終わらない場合、RedPen は実装された機能をロードできません。 以下、Validator を追加する方法とプラグインの作り方について解説します。 |
Validator を RedPen のソースに追加
ではさっそく、簡単な Validator (PlainSentenceLengthValidator)を実装してみましょう。 PlainSentenceLengthValidator は文書内に存在する文が百文字もしくはそれ以上続く場合、エラーを出力します。 実装したのち、PlainSentenceLengthValidator を RedPen のソースに追加します。
PlainSentenceLengthValidator
PlainSentenceLengthValidator クラスをパッケージ’cc.redpen.validator.sentence’に作成します。 このときクラスは 'redpen/redpen-core/src/main/java/cc/redpen/validator/sentence/' ディレクトリに保存します。
以下は PlainSentenceLengthValidator クラスの実装となります。
package cc.redpen.validator.sentence;
/**
* Validate input sentences contain more characters more than specified.
*/
public class PlainSentenceLengthValidator extends Validator {
/**
* Default constructor initializes properties with their default values.
*/
public PlainSentenceLengthValidator() {
super("max_len", 30); // Default maximum length of sentences.
@Override
public void validate(Sentence sentence) {
if (sentence.getContent().length() > getInt("max_len")) {
addValidationError(sentence, sentence.getContent().length(), maxLength);
}
}
}PlainSentenceLengthValidator は validate (引数= Sentence オブジェクト)メソッドを実装しています。 PlainSentenceLengthValidator が設定ファイルに追加されると、RedPen は実装した validate メソッドを実行します。 Sentence が引数なので、RedPen は入力文書の文すべてを引数としてくりかえし実行します。
実装した Validator を適用する
では設定ファイルに作成した機能を追加しましょう。設定ファイルにはクラス名からサフィックス Validator をのぞいて追加します。 以下、PlainSentenceLengthValidator を設定に追加しています。
<redpen-conf>
<validator>
...
<validator name="PlainSentenceLength" />
...
</validator>
</redpen-conf>プラグインの作成
プラグイン作成で重要なファイルは pom.xml です。 pom.xml はビルドツール、Maven の設定ファイルです。以下は pom.xml の例です。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>redpen.cc</groupId>
<artifactId>hankaku-kana-validator</artifactId>
<version>1.0-SNAPSHOT</version>
<name>hankaku-kana-validator</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>redpen.cc</groupId>
<artifactId>redpen-core</artifactId>
<version>1.4</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/redpen-core-1.4.jar</systemPath>
</dependency>
</dependencies>
</project>プラグインを作るには上の pom.xml ファイルがほぼそのまま利用できます。 変更する点は artifactId 、name 要素です。あなたの機能名になるよう名前を変更しましょう。
これで pom.xml が編集できました。編集した機能用のファイルを"main/java/cc/redpen/validator/sentence" (sentence)にコピーします。 上記で解説しましたように、機能用のクラスは Validator クラスを継承する必要があります。
Validator の実装ファイルをコピーすると、ビルドができます。以下のコマンドでプラグインを作成しましょう。
$ mvn install作成したプラグインを利用する
無事 mvn コマンドによるビルドが成功しました。これで target ディレクトリにプラグイン用 jar ファイルが生成されます。 プラグイン用 jar ファイルを RedPen のクラスパスが含まれるディレクトリ($REDPEN_HOME/lib など)にコピーします。 作成したプラグインが設定ファイルに追加されると、RedPen は実装した validate メソッドを実行します。
JavaScript による拡張の作成
バージョン1.3から任意の JavaScript を Validator として実行する、JavaScriptValidator がサポートされました。JavaScript による Validator の作成にあたってはビルド作業が必要ありません。そのためユーザはより気軽に RedPen の Validator を作成できます。
JavaScriptValidator を有効にする
JavaScriptValidator を使うのは簡単です。使うには <validator name="JavaScript"/> を設定ファイルへ追記します。以下は追記する例です。
<redpen-conf lang="ja">
<validators>
...
<validator name="JavaScript" />
</validators>
</redpen-conf>機能の実装
JavaScriptValidator は $REDPEN_HOME/js ディレクトリから JavaScript ファイル(.js)を検索し、全て実行します。JavaScriptValidator が JavaScript ファイルを検索するディレクトリは script-path プロパティで指定できます。
文書の検査にあたり、JavaScriptValidator は 各 JavaScript ファイルに定義された関数を順次呼び出します。呼び出される関数は以下のシグニチャを持ちます。
function preValidateSentence(sentence) {
}
function preValidateSection(section) {
}
function validateDocument(document) {
// your validation logic for document here
}
function validateSentence(sentence) {
// if ( ... sentenceについて検査を実行 ... ) {
// // 検査に失敗
// addError('エラーについて報告', sentence);
// }
}
function validateSection(section) {
// sectionに対する検査処理を記述する
}Validator の作成例
以下は、NumberOfCharacterValidator を JavaScript で作成した例です。
var MIN_LENGTH = 100;
var MAX_LENGTH = 1000;
function validateSentence(sentence) {
if (sentence.getContent().length() < MIN_LENGTH) {
addError("Sentence is shorter than "
+ MIN_LENGTH + " characters long.", sentence);
}
if (sentence.getContent().length() > MAX_LENGTH) {
addError("Sentence is longer than " + MAX_LENGTH
+ " characters long.", sentence);
}
}上の例は Java 版と似ています。しかし型システムの違いによって Java 版における validate(Sentence sentence) 関数が、JavaScript 版では validateSentence(sentence) と呼ばれています。
実行
redpen コマンドを実行すると JavaScript による Validator の実行ができます。以下は例で作成した JavaScript ファイルを Validator として実行する、コマンドラインの例です。上の例で作成した JavaScript ファイルを $REDPEN_HOME/js ディレクトリ以下に置いてください。
$ ./bin/redpen -c myredpen-conf.xml 2be-validated.txt
2be-validated.txt:1: ValidationError[JavaScript], [NumberOfCharacter.js] Sentence is shorter than 100 characters long. at line: very short sentence.JavaScriptValidator にパラメタ(プロパティ)を渡す
バージョン 1.7 より JavaScript で記述された機能にプロパティを渡せるようになりました。プロパティを渡すことで、機能の挙動を修正できます。プロパティ JavaScript 機能の設定ブロックに記述します。以下の例ではプロパティ max_char_num を 5 に設定しています。
<validator name="JavaScript"> <property name="max_char_num" value="5" /> </validator>
JavaScript ブロックに登録されたプロパティは JavaScript 拡張から抽出できます。以下の JavaScript 機能拡張はプロパティ、 max_char_num の値を getInt メソッドで取り出しています。
function validateSentence(sentence) {
var content = sentence.getContent().split(" ");
var limit= getInt("max_char_num");
for(var i = 0; i<content.length;i++){
if(content[i].length >= limit){
addError("word [" + content[i] +"] is too long. length: " + content[i].length, sentence);
}
}
}
プロパティを取り出すメソッドは型ごとに存在します。以下、サポートしている get メソッドの一覧です。
| メソッド名 | 型 |
|---|---|
|
Int |
|
Float |
|
String |
|
Boolean |
|
Set |
文書モデル
本節では RedPen が内部に保持する文書モデルについて解説します。 RedPen は多様なテキストフォーマットをサポートします。 各種の入力文書は RedPen 内部で文書モデルというブロック(クラス)群に変換されます。
生成された内部文書モデルは以下のブロックからなります。
-
Document 1つ以上の節を持つファイル
-
Section 文書内の節に相当する。複数のブロック(見出し, パラグラフ, リスト)を保持する。
-
Header 見出し文
-
Paragraph パラグラフに相当(複数の文を保持する)
-
ListBlock リスト要素(ListElement)を保持する
以下のイメージは RedPen が内部で使用する文書モデルです。

RedPen における言語の設定
RedPen は入力文書がどのような自然言語(ドイツ語・フランス語・日本語など)で記述されていても処理できます。ただしデフォルトでは英語を代表とする、ラテン系言語用の設定です。そのため、日本語などで書かれた文書を処理するには、設定ファイルで言語を指定する必要があります。
言語設定の修正
言語設定には、現在3つの値が指定できます。指定できる値は "en" 、 "ja"、"ru" です。"en" は英語やドイツ語など、ラテン系の言語で書かれた文書を意味します。"ja" は日本語、"ru" はロシア語を意味します。
言語設定を修正するには、設定ファイルの symbols ブロックにある lang プロパティを変更します。以下は文書の言語設定に日本語("ja")を指定する例です。
<symbols lang="ja">
<symbol name="EXCLAMATION_MARK" value="!" invalid-chars="!" after-space="true" />
<symbol name="LEFT_QUOTATION_MARK" value="\'" invalid-chars="“" before-space="true" />
<symbol name="RIGHT_QUOTATION_MARK" value="\'" invalid-chars="”" after-space="true" />
<symbol name="NUMBER_SIGN" value="#" invalid-chars="#" after-space="true" />
<symbol name="FULL_STOP" value="。" invalid-chars=".." after-space="true" />
<symbol name="COMMA" value="、" invalid-chars="," after-space="true" />
</symbols>シンボル設定のオーバーライド
文書の内容や著者の好みによって、文書中で使用される文字や記号(シンボル)は異なります。例えば左側のシングルクォーテーションとして、ある著者が「'」を使用するところで、また別の著者は「‘」を使用したいかもしれません。
この問題に対処するために、RedPen は文書中で使用するシンボルの設定(デフォルト設定はシンボル設定節を参照)を修正する方法を提供しています。文字の設定では、文書中に出現してはならないシンボルもあわせて指定できます。
以下は、シングルクォーテーションに「'」の使用する設定例です。
<symbols>
<symbol name="LEFT_SINGLE_QUOTATION_MARK" value="'" invalid-chars="‘" />
<symbol name="RIGHT_SINGLE_QUOTATION_MARK" value="'" invalid-chars="’"/>
</symbols>RedPen サーバ
RedPen サーバは RedPen が提供する機能のほとんどを HTTP REST API としてサポートしてます。
RedPen サーバの起動・終了方法
RedPen コマンド節を参照してください。
Heroku ボタンによるサーバ起動
Heroku を利用するとローカル環境でのサーバ管理が必要ないので便利です。RedPen サーバは Heroku ボタンを利用すると数クリックで立ち上がります。 RedPen プロジェクト README の一番下にある、Heroku ボタンをクリックします。

Heroku ボタンをクリックすると、RedPen サーバが Heroku 環境(http://*.herokuapp.com)に立ち上がり、利用できる状態になります。実は RedPen のホームページにある RedPen サンプルサーバ も Heroku 環境で動作しています。
RedPen サーバ API
設定を表示
/rest/config/redpens はあらかじめ定義された redpens メソッドで利用できる設定を返します。
GET パラメタ
-
lang=xx を設定すると、指定された言語の設定(JSON フォーマット)だけが返されます。 lang を指定しない場合には、対応する言語の設定すべてが返されます。
以下は返された JSON の例となります。
{
"version": "1.1.2",
"documentParsers": ["PLAIN", "MARKDOWN", "WIKI"],
"redpens": {
"en": {
"lang": "en",
"tokenizer": "cc.redpen.tokenizer.WhiteSpaceTokenizer",
"validators": {
"CommaNumber": { "languages": [], "properties": {} },
"Contraction": { "languages": ["en"], "properties": {} },
"DoubledWord": { "languages": [], "properties": {} },
"EndOfSentence": { "languages": ["en"], "properties": {} },
"InvalidExpression": { "languages": [], "properties": {} },
"InvalidSymbol": { "languages": [], "properties": {} },
"InvalidWord": { "languages": ["en"], "properties": {} },
"ParagraphNumber": { "languages": [], "properties": {} },
"Quotation": { "languages": ["en"], "properties": {} },
"SectionLength": { "languages": [], "properties": {"max_char_num": "2000"} },
"SentenceLength": { "languages": [], "properties": {"max_len": "200"} },
"SpaceBetweenAlphabeticalWord": { "languages": [], "properties": {} },
"Spelling": { "languages": [], "properties": {} },
"StartWithCapitalLetter": { "languages": ["en"], "properties": {} },
"SuccessiveWord": { "languages": [], "properties": {} },
"SymbolWithSpace": { "languages": [], "properties": {} },
"WordNumber": { "languages": [], "properties": {} }
}
},
"ja": {
"lang": "ja",
"tokenizer": "cc.redpen.tokenizer.JapaneseTokenizer",
"validators": {
"CommaNumber": { "languages": [], "properties": {} },
"DoubledWord": { "languages": [], "properties": {} },
"HankakuKana": { "languages": ["ja"], "properties": {} },
"InvalidSymbol": { "languages": [], "properties": {} },
"KatakanaEndHyphen": { "languages": ["ja"], "properties": {} },
"KatakanaSpellCheck": { "languages": ["ja"], "properties": {} },
"ParagraphNumber": { "languages": [], "properties": {} },
"SectionLength": { "languages": [], "properties": {"max_num": "1500"} },
"SentenceLength": { "languages": [], "properties": {"max_len": "100"} },
"SpaceBetweenAlphabeticalWord": { "languages": [], "properties": {} },
"SuccessiveWord": { "languages": [], "properties": {} }
}
}
}
}-
version は RedPen のバージョンをあらわします。
-
documentParsers 配列はサポートされる文書パーサ(文書フォーマット)をあらわします。
-
redpens はあらかじめ言語ごとに定義された RedPen がどのように設定されているかをあらわします。
-
lang は対象となる言語をしめします。
-
tokenizer は redpen によって利用される Tokenizer をあらわします。
-
validators は文書に適用される機能集合です。各オブジェクトは以下の要素をもちます。
-
languages は機能がサポートする言語からなる配列です。配列が空の場合には、任意の言語対応していることをあらわします。
-
properties は機能で指定された設定値をしめします。
-
-
文書検査(XML)
/rest/document/validate は POST リクエストで文書を検査します。検査が終了した後、発見されたエラーを返します。
POST パラメタ
-
document には RedPen に検査させたい文書(テキスト)を追加します。
-
documentParser にはパーサを指定します。現在対応しているパーサは以下のものがあります。
-
PLAIN
-
MARKDOWN
-
WIKI
-
ASCIIDOC
-
LATEX
-
-
lang には入力文書の言語を指定します。現在、ja (日本語)と en (英語)がサポートされています。
-
(オプション)format には出力フォーマットを指定します。指定できるフォーマットに以下のものがあります
-
json (デフォルト)
-
json2
-
plain
-
plain2
-
xml
-
-
config には RedPen の設定内容(XML)を追加します。
curl コマンドを利用して document/validate をつかってみる
$ curl --data document="Twas brillig and the slithy toves did gyre and gimble in the wabe" \
--data lang=en --data format=PLAIN2 \
--data config="`cat ./redpen-server/target/classes/conf/redpen-conf.xml`" \
localhost:8080/rest/document/validate/
Line: 1, Offset: 0
Sentence: Twas brillig and the slithy toves did gyre and gimble in the wabe
Spelling: Found possibly misspelled word "brillig".
Spelling: Found possibly misspelled word "slithy".
Spelling: Found possibly misspelled word "toves".
Spelling: Found possibly misspelled word "gyre".
Spelling: Found possibly misspelled word "gimble".
Spelling: Found possibly misspelled word "wabe".
DoubledWord: Found repeated word "and".$ curl -s --data document="古池や,蛙飛び込む水の音" \
--data config="`cat ./redpen-server/target/classes/conf/redpen-conf-ja.xml`" \
localhost:8080/rest/document/validate/ | json_reformat
{
"errors": [
{
"sentence": "古池や,蛙飛び込む水の音",
"endPosition": {
"offset": 4,
"lineNum": 1
},
"validator": "InvalidSymbol",
"lineNum": 1,
"sentenceStartColumnNum": 0,
"message": "Found invalid symbol \",\".",
"startPosition": {
"offset": 3,
"lineNum": 1
}
}
]
}文書検査(JSON)
/rest/document/validate/json は POST リクエストを受け取ります。検査が終了すると結果を返します。設定は JSON フォーマットでおこないます。
Request フォーマット
{
"document": "Theyre is a blak rownd borl.",
"format": "json2",
"documentParser": "PLAIN",
"config": {
"lang": "en",
"validators": {
"CommaNumber": {},
"Contraction": {},
"DoubledWord": {},
"EndOfSentence": {},
"InvalidExpression": {},
"InvalidSymbol": {},
"InvalidWord": {},
"ParagraphNumber": {},
"Quotation": {},
"SectionLength": {
"properties": {
"max_char_num": "2000"
}
},
"SentenceLength": {
"properties": {
"max_len": "200"
}
},
"SpaceBetweenAlphabeticalWord": {},
"Spelling": {},
"StartWithCapitalLetter": {},
"SuccessiveWord": {},
"SymbolWithSpace": {},
"WordNumber": {}
},
"symbols": {
"AMPERSAND": {
"after_space": false,
"before_space": true,
"invalid_chars": "&",
"value": "&"
},
"ASTERISK": {
"after_space": true,
"before_space": true,
"invalid_chars": "*",
"value": "*"
}
}
}
}-
document には入力文書の内容を追加します。
-
document には RedPen に検査させたい文書(テキスト)を追加します。
-
documentParser にはパーサを指定します。現在対応しているパーサは以下のものがあります。
-
PLAIN
-
MARKDOWN
-
WIKI
-
ASCIIDOC
-
LATEX
-
-
format には出力フォーマットを指定します。指定できるフォーマットに以下のものがあります。
-
json (デフォルト)
-
json2
-
plain
-
plain2
-
xml
-
-
config には RedPen の設定を JSON フォーマットで指定します。 config にはいくつかの要素が含まれます。
-
validators には validator 要素を追加し機能名リストを追加します。機能名ブロックには properties を追加し設定を行えます。
-
lang は入力文書の言語を指定します。
-
symbols ではシンボル設定の変更を行います。各要素はシンボル名からなるブロックです。シンボル名ブロックには以下の要素が追加されます。
-
value specifies the Symbol’s value
-
invalid_chars is a string of invalid alternatives for this Symbol
-
before_space and after_space specify if a space is required before or after the Symbol.
-
-
以下、/document/validate/json で検査した結果の例(json2 format)となります。
{
"errors": [
{
"sentence": "Theyre is a blak rownd borl.",
"position": {
"start": {
"offset": 0,
"line": 1
},
"end": {
"offset": 27,
"line": 1
}
},
"errors": [
{
"subsentence": {
"offset": 0,
"length": 6
},
"validator": "Spelling",
"position": {
"start": {
"offset": 0,
"line": 1
},
"end": {
"offset": 6,
"line": 1
}
},
"message": "Found possibly misspelled word \"Theyre\"."
},
{
"subsentence": {
"offset": 12,
"length": 4
},
"validator": "Spelling",
"position": {
"start": {
"offset": 12,
"line": 1
},
"end": {
"offset": 16,
"line": 1
}
},
"message": "Found possibly misspelled word \"blak\"."
},
{
"subsentence": {
"offset": 17,
"length": 5
},
"validator": "Spelling",
"position": {
"start": {
"offset": 17,
"line": 1
},
"end": {
"offset": 22,
"line": 1
}
},
"message": "Found possibly misspelled word \"rownd\"."
},
{
"subsentence": {
"offset": 23,
"length": 4
},
"validator": "Spelling",
"position": {
"start": {
"offset": 23,
"line": 1
},
"end": {
"offset": 27,
"line": 1
}
},
"message": "Found possibly misspelled word \"borl\"."
}
]
}
]
}curl コマンドを利用して document/validate/json をつかってみる
$ curl -s --data "document=fish and chips" http://localhost:8080/rest/document/validate | json_reformat
{
"errors": [
{
"sentence": "fish and chips",
"validator": "StartWithCapitalLetter",
"lineNum": 1,
"sentenceStartColumnNum": 0,
"message": "Sentence starts with a lowercase character \"f\"."
}
]
}$ curl -s --data "document=ここはどこでうか?&lang=ja&" http://localhost:8080/rest/document/validate | json_reformat
{
"errors": [
{
"sentence": "ここはどこでうか?",
"endPosition": {
"offset": 9,
"lineNum": 1
},
"validator": "InvalidSymbol",
"lineNum": 1,
"sentenceStartColumnNum": 0,
"message": "Found invalid symbol \"?\".",
"startPosition": {
"offset": 8,
"lineNum": 1
}
}
]
}$ curl -s --data "document=# Markdown Test%0A%0ASpellink Errah&lang=en&documentParser=MARKDOWN" http://localhost:8080/rest/document/validate | json_reformat
{
"errors": [
{
"sentence": "Spellink Errah",
"endPosition": {
"offset": 8,
"lineNum": 3
},
"validator": "Spelling",
"lineNum": 3,
"sentenceStartColumnNum": 0,
"message": "Found possibly misspelled word \"Spellink\".",
"startPosition": {
"offset": 0,
"lineNum": 3
}
},
{
"sentence": "Spellink Errah",
"endPosition": {
"offset": 14,
"lineNum": 3
},
"validator": "Spelling",
"lineNum": 3,
"sentenceStartColumnNum": 0,
"message": "Found possibly misspelled word \"Errah\".",
"startPosition": {
"offset": 9,
"lineNum": 3
}
}
]
}curl -s -H "Content-Type: application/json" \
--data '{document:"fisch and chipps",format:"plain",config:{validators:{Spelling:{},SentenceLength:{properties:{max_len:6}}}}}' \
http://localhost:8080/rest/document/validate/json
1: ValidationError[Spelling], Found possibly misspelled word "fisch". at line: fisch and chipps
1: ValidationError[Spelling], Found possibly misspelled word "chipps". at line: fisch and chipps
1: ValidationError[SentenceLength], The length of the sentence (16) exceeds the maximum of 6. at line: fisch and chippsRedPen の開発について
GitHub を通したフィーチャリクエストを歓迎しています。開発に参加したい方は以下の情報を参考にしてください。 RedPen の開発環境を構築するために必要な情報を記載しています。修正はプルリクエストの形でいただけると master ブランチにマージしやすくなります。
開発ポリシー
RedPen の開発ポリシーは、「ゆっくりと着実に」です。そのため大きな変更が予想される提案は、受け入れできない場合があります。ご了承ください。
RedPen のビルド
RedPen パッケージのビルドでは Maven を使用します。パッケージ全体をビルドするには以下のコマンドを実行します。
$ ./mvnw install
ビルドされるとパッケージが出力されます。出力される場所は redpen/redpen-distribution/target/redpen-distribution-..*-SNAPSHOT-assembled.tar.gz です。
出力されたパッケージを使用するまえに、パッケージを展開します。以下はパッケージを展開する例です。
$ cd redpen/redpen-distribution/target $ tar xvf redpen-distribution-*.*.*-SNAPSHOT-assembled.tar.gz x redpen-distribution-*.*.*-SNAPSHOT/bin/ x redpen-distribution-*.*.*-SNAPSHOT/conf/ x redpen-distribution-*.*.*-SNAPSHOT/js/ x redpen-distribution-*.*.*-SNAPSHOT/js/test/ x redpen-distribution-*.*.*-SNAPSHOT/lib/ ...
これでパッケージを使用する準備が整いました。以下はパッケージに含まれる redpen コマンドを使用する例です。
$cd redpen-distribution-*.*.*-SNAPSHOT
$bin/redpen -h
usage: redpen-cli [Options] [<INPUT FILE>]
-c,--conf <CONF FILE> Configuration file (REQUIRED)
-f,--format <FORMAT> Input file format
(markdown,plain,wiki,asciidoc,latex)
-h,--help Displays this help information and exits
-l,--limit <LIMIT NUMBER> error limit number
-r,--result-format <RESULT FORMAT> Output result format
(json,json2,plain,plain2,xml)
-v,--version Displays version information and exits
RedPen のテスト
RedPen のソースコードを変更する場合、必ず対応するテストケースを追加してください。レビューアが期待される挙動をテストから推測できます。加えて、プルリクエストを作成するにあたり(変更した箇所だけでなく)全テストケースが正常に実行されることを確認してください。RedPen の全テストケースを実行するコマンドを次に示します。
$./mvnw test
その他の情報
-
Twitter アカウント
-
ソースコードリポジトリ(git)
-
チャット(日本語)
-
Issue トラッカー
RedPen FAQ
-
RedPen は LaTeX に対応していますか。
はい、バージョン1.4から対応を開始しました。
$ redpen -c redpen-conf.xml -f latex content.tex -
RedPen が出力するエラーが多いです。
RedPen はまちがってエラーを出力してしまう箇所があります。アノテーションを利用すると指定したエラーを抑制できます(くわしくはこちらを参照してください)。
-
RedPen の設定方法で参考となる文書プロジェクトはありますか。
-
RedPen の拡張を作りたいのですが、参考になる資料はありますか。
まずは "RedPen を拡張する" をご一読ください。拡張を作る上で、以下の資料とプロジェクトが参考になります。
-
参考になる記事
-
参考になるプロジェクト
-
-
RedPen の利用方法で参考になる記事はありますか。
以下の記事が参考になります。